 SQL Server has a few functions that allow calculating a hash from a single value or multiple values. They could be very useful if they worked reliably. Unfortunately, they do not. This article shows how to use CHECKSUM and BINARY_CHECKSUM functions and why you should not rely on them. And I do not only mean the collision probability!
SQL Server has a few functions that allow calculating a hash from a single value or multiple values. They could be very useful if they worked reliably. Unfortunately, they do not. This article shows how to use CHECKSUM and BINARY_CHECKSUM functions and why you should not rely on them. And I do not only mean the collision probability!
What is BINARY_CHECKSUM
Both CHECKSUM and BINARY_CHECKSUM calculate a checksum for a row or a list of values. For example:
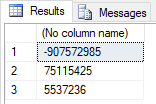
select checksum(2), checksum('dfga', 4), checksum(getDate(), 'OVdovudwkda4', 'ddsdg')

select binary_checksum(*)
from USERS
 The idea is to shorten the input parameters to a single value that is easy to compare.
The idea is to shorten the input parameters to a single value that is easy to compare.
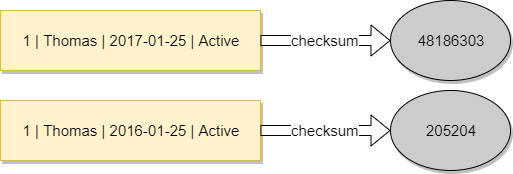
If two sets have different checksums, it means that they are different.
It seems like a perfect solution when you have a table with multiple columns and you need a way to easily check which rows changed or to find duplicates. It should be enough to calculate a checksum for each row, save them somewhere and after a while do the same and compare the results. The rows for which the previous and the current checksums are different, have changed.
Collision probability problem
From mathematical point of view it is obvious that the same checksum does not imply identity of the rows. A checksum means shortening information from the input which is the same as loosing a part of it. For example 1024 bytes of information is shortened to 4 bytes (int). It must mean that many different inputs exist that produce the same checksum. Actually, for some (or even all) checksums there are infinite number of inputs that can be shortened to them using BINARY_CHECKSUM function.
Moreover, the collision probability is pretty high as there are only 4 bytes for a checksum in SQL Server.
Sign of numbers with decimal part
The probability is not the worst problem of BINARY_CHECKSUM in my opinion. There are ways to build different inputs with the same checksum on purpose. One of the methods is changing a sign of a number with a decimal part.
select binary_checksum(2, 2.1), binary_checksum(2, -2.1)
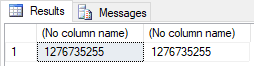
select binary_checksum(1000.23), binary_checksum(-1000.23)
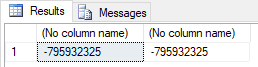
What is interesting, if the number is an integer, the checksums are different.
Long texts
BINARY_CHECKSUM uses only first 255 characters of data that is varchar(max). It means that only the first 255 characters have to be the same to give the same checksum.
declare @text nvarchar(max) = 'abcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyzabcdefghijklmnoprstuvwxyz'
select binary_checksum(@text),
binary_checksum(@text + '123')
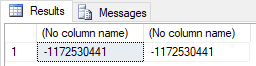
The second text is not only different, it is even longer but the checksum is the same.
The same checksum does not imply the same input
Checksums can be used only in one direction - if the checksums are different, the inputs are different. The same checksums mean nothing and collisions are not as rare as they seem to be.
If you decide to use CHECKSUM or BINARY_CHECKSUM in SQL Server, you must remember about the issues above. Unfortunately, they are inappropriate for many applications e.g. finding changed rows - they may skip some modifications.