 A concept of indexes is almost the same in the whole relational databases world. It could mean, it is perfect as nobody has invented anything spectacular in this area for a long time. Spectacular? Agreed, perhaps not spectacular, but still worth to consider using is a small enhancement to the commonly known b-tree index - a filtered index.
A concept of indexes is almost the same in the whole relational databases world. It could mean, it is perfect as nobody has invented anything spectacular in this area for a long time. Spectacular? Agreed, perhaps not spectacular, but still worth to consider using is a small enhancement to the commonly known b-tree index - a filtered index.
Filtered index is a feature of SQL Server that makes this database special among others. The biggest competitor, Oracle, does not have it (but there is a workaround). So what filtered indexes are?
Concept of filtered indexes
A commonly used index in SQL Server is a physical structure that contains values from a chosen set of columns from all rows in a table. Most of the time, the structure is a b-tree and the values are stored in the nodes and leaves in such a way that looking for (seeking) a particular value in the tree is quite fast. It is starting from the root and going down through nodes deciding each time which branch to choose. In spite of it is a passionate topic, I am not going to fully describe how indexes are structured. For purpose of this article, it is enough to know that each value from the indexed column has its own place in the b-tree. If the table is big, the indexed column has many values and the index has many nodes. Adding a new row to the table, makes the table bigger but also the index grows. There are some more or less obvious consequences:
- The index grows and consumes more disk space.
- A bigger index is more difficult to search through - seeks and scans are slower.
- Rebuilding a big index requires more time and resources.
Of source, indexing is an excellent invention. It makes seeking (looking for a particular value) possible. If a column is indexed, the database does not need to read all the rows from the table to find one with a particular value in the indexed column. However, big indexes are big problems. Sometimes you know that the table has some specific rows that you are not going to query for. What if I could index not all rows but only a subset of them? This is exactly what filtered indexes are.
Example with no index
Hmm ... let me illustrate this with an example.
I have a table with messages that users send to other users. When a message is read by a receiver, it is marked as read by switching mes_unread field from 1 to 0.
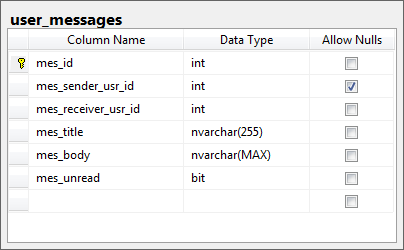
I already have 1 million rows in the table. When a user logs into his/her account, unread messages are displayed. A direct effect of this is that the very frequent query is the following one:
SELECT *
FROM user_messages
WHERE mes_receiver_usr_id = ?
AND mes_unread = 1
Currently, there is only one index on this table - a clustered index on mes_id. Hence, there is no surprise that an execution plan for a sample run shows Clustered Index Scan which is reading all data looking for rows that match the conditions.
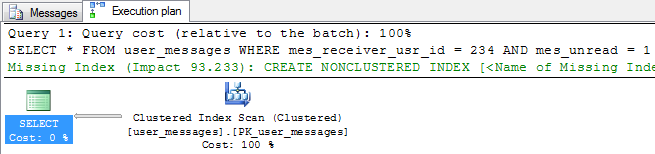
An estimated query cost is 10.6818. It is not good that the most often used query reads all rows from the table.
Before I go any further, I will check a size of the table using sp_spaceused procedure.
EXEC sp_spaceused 'user_messages';

It shows that the table data consumed about 103 MB of storage and the clustered index - 392 KB.
Traditional index
Going back to the Clustered Index Scan issue, there is a simple solution to this - create an index. What index? For example the one suggested by the database engine presented with a green font on the execution plan:
CREATE NONCLUSTERED INDEX IX_mes_receiver_usr_id_unread
ON user_messages (mes_receiver_usr_id, mes_unread);
After the index creation, the same query executes more efficiently. The execution plan shows that the scan was replaced with the seek operation using the index and the key lookup. It is much better choice in my case.
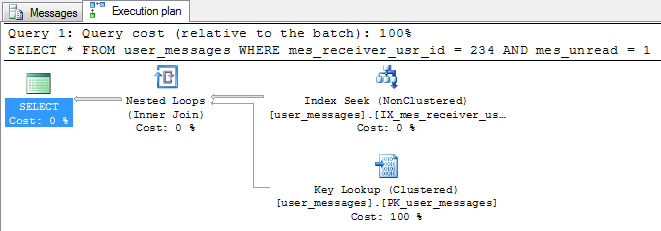
A cost of the query is estimated to 1.20738. It is 9 times less than without the index.
sp_spaceused reports additional 15 MB used to store the index.

15 MB is not much but the table takes only 103 MB. If the table was 10 GB, I could expect the index to be 1.5 GB which would be noticeable. Do I really need an index that size? Are all information stored in the index useful for my system?
Filtered index
Let's continue story telling about my system. Users are very active and they usually read messages shortly after receiving them so most of them have already been read (95%). Only 5% of the messages have not yet been opened. It means that the condition AND mes_unread = 1 reduces the number of returned rows 20 times (to 5%). Going further, I do not need that part of the index that contains information about the rows with mes_unread = 0. Fortunately, SQL Server contains the filtered index functionality which allows me to reduce a number of rows used to build the index.
At this point, I will replace the current index with a filtered index.
DROP INDEX IX_mes_receiver_usr_id_unread ON user_messages;
CREATE NONCLUSTERED INDEX IX_mes_receiver_usr_id_unread
ON user_messages (mes_receiver_usr_id, mes_unread)
WHERE mes_unread = 1;
A filtered index can be easily recognized by the WHERE clause in the definition. The construction used above creates an index on two columns: mes_receiver_usr_id and mes_unread but only for those rows where mes_unread = 1. Other rows that do not match it are not included. They simply do not occupy disk space in the index.
Before I start eulogizing filtered indexes, I will check the execution plan.
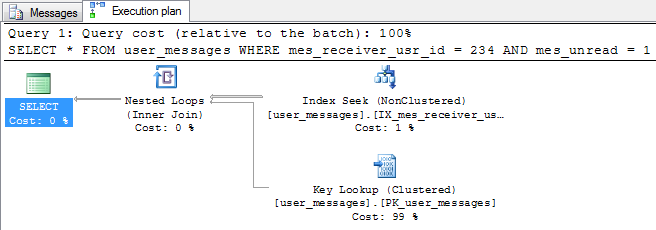
It looks very similar to the previous one. So what is a difference? The difference is the execution cost. It went down to 0.246134 which is almost five times less than with the traditional index. Why? The answer is in the index size which can be checked with sp_spaceused.
EXEC sp_spaceused 'user_messages';

1.1 MB in case of the filtered index is significantly less when compared to 15 MB of the traditional index. It directly answers smaller execution cost - smaller index, faster seeking.
Below you can find statistics of all three cases gathered together.
| Case | Execution cost | Index size |
| No index | 10.6818 | - |
| Index | 1.2073 | 15.3 MB |
| Filtered index | 0.2461 | 1.1 MB |
I know I wrote that already but to make this article complete, I need to emphasize that the filtered index does not contain representation of all rows from the table. It can be an advantage: smaller storage usage, faster seeking, but there is also a disadvantage - changing the value in the WHERE clause may make the index useless. For example, if I wanted to query for messages that have already been read, this index would not help me:
SELECT *
FROM user_messages
WHERE mes_receiver_usr_id = 234
AND mes_unread = 0;
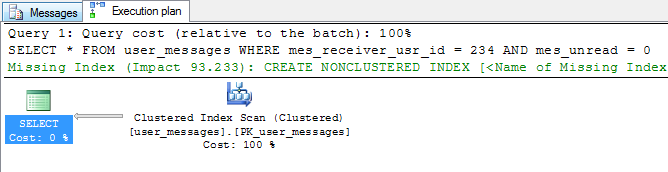
As you can see above, changing the condition from mes_unread = 1 to mes_unread = 0 cause switching from seeking to scanning. At this point the reason should be obvious - the filtered index does not have any information about the rows with mes_unread = 0 so it cannot be used.
Conclusions
Filtered indexes have great power. They can help a lot if you have tables that most of the rows are almost never queried for. They do not only consume less storage space but they are also faster as they are smaller. On the other hand, I have very rarely used filtered indexes. When wondering why, I came to a conclusion that if a majority of rows are never queried why to keep them? If you need them but very occasionally, you can archive them in other table. Referring to my example - to archived_user_messages table.
I have not needed to use this feature often, but you may have a case when it ideally fits.