 Majority of the most popular databases have some mechanisms to generate numbers that database developers use as values in primary key columns. Oracle has sequences, MySQL has autoincrement, SQL Server has used IDENTITY property for many years. Before SQL Server 2012 there was no other option. Obviously, a developer could implement his/her own mechanism but that does not count.
Majority of the most popular databases have some mechanisms to generate numbers that database developers use as values in primary key columns. Oracle has sequences, MySQL has autoincrement, SQL Server has used IDENTITY property for many years. Before SQL Server 2012 there was no other option. Obviously, a developer could implement his/her own mechanism but that does not count.
SQL Server 2012 was the first release that provided another built-in solution – a sequence. SQL Server community was really excited about this new feature as the old IDENTITY property has some limitations which sequence objects do not have. Although usability is important and a sequence is probably a winner in this category, there are concerned voices raised about performance. Is using a sequence as fast as IDENTITY property? Let’s test it out.
Test scenario
IDENTITY property is simple to use. There are no many options – you specify the first number (seed) and a value that is added to the previous value to generate the next one (increment). For this test purpose, I use IDENTITY (1, 1) statement.
A sequence object has more options. Besides the first number and increment it allows cache configuration. Cache was designed for improving performance of sequence numbers generation. Hence, I decided to include different cache settings in the test. Finally, I tested six different cache settings for sequences:
- No cache.
- Cache 10 – when a sequence object is queried for a new value for the first time, the sequence is incremented by 10 and 1 value is returned to the requestor. If the sequence is queried again, database engine does not need to go to the sequence, because it is already set to 10 – the second value can be retrieved from the cache.
It means, generating 1000 numbers requires updating the sequence 100 times. - Cache 100 – a sequence object increments by 100 at once. Generating 1000 numbers requires updating the sequence only 10 times.
- Cache 1000.
- Cache 10000.
- Cache 100000.
Besides a test of IDENTITY and six versions of a sequence, there is also a referential test case called simple. It has hardcoded values. I added it to compare an overhead of generating numbers in different ways to not generating numbers at all.
Each case has its own table. A script creating them is below:
create table simpleTable (
value1 int,
value2 int,
text1 varchar(100))
GO
create table tableIdentity (
value1 int identity(1, 1),
value2 int,
text1 varchar(100))
GO
create sequence seqNoCache
as int
start with 1
increment by 1
no cache;
create table tableSeqNoCache (
value1 int default (next value for seqNoCache),
value2 int,
text1 varchar(100)
)
GO
create sequence seqCache10
as int
start with 1
increment by 1
cache 10;
create table tableSeqCache10 (
value1 int default (next value for seqCache10),
value2 int,
text1 varchar(100)
)
GO
create sequence seqCache100
as int
start with 1
increment by 1
cache 100;
create table tableSeqCache100 (
value1 int default (next value for seqCache100),
value2 int,
text1 varchar(100)
)
GO
create sequence seqCache1000
as int
start with 1
increment by 1
cache 1000;
create table tableSeqCache1000 (
value1 int default (next value for seqCache1000),
value2 int,
text1 varchar(100)
)
GO
create sequence seqCache10000
as int
start with 1
increment by 1
cache 10000;
create table tableSeqCache10000 (
value1 int default (next value for seqCache10000),
value2 int,
text1 varchar(100)
)
GO
create sequence seqCache100000
as int
start with 1
increment by 1
cache 100000;
create table tableSeqCache100000 (
value1 int default (next value for seqCache100000),
value2 int,
text1 varchar(100)
)
GO
Each case inserts 1 000 000 rows with numbers generated in a specific way into a table. Scripts that do that are presented below:
- perfSimple.sql
set nocount on;
GO
declare @startTime datetime = getDate();
declare @iterNo int = 1;
while @iterNo < 1000000 begin
insert into simpleTable (value1, value2, text1)
values (1, 2, 'test');
set @iterNo += 1;
end;
declare @endTime datetime = getDate();
declare @duration int = datediff(second, @startTime, @endTime);
print @duration;
GO - perfSeqNoCache.sql
set nocount on;
GO
declare @startTime datetime = getDate();
declare @iterNo int = 1;
while @iterNo < 1000000 begin
insert into tableSeqNoCache (value2, text1)
values (2, 'test');
set @iterNo += 1;
end;
declare @endTime datetime = getDate();
declare @duration int = datediff(second, @startTime, @endTime);
print @duration;
GO - perfSeqCache10.sql
set nocount on;
GO
declare @startTime datetime = getDate();
declare @iterNo int = 1;
while @iterNo < 1000000 begin
insert into tableSeqCache10 (value2, text1)
values (2, 'test');
set @iterNo += 1;
end;
declare @endTime datetime = getDate();
declare @duration int = datediff(second, @startTime, @endTime);
print @duration;
GO - perfSeqCache100.sql
... similar to perfSeqCache10.sql but on a different table ... - perfSeqCache1000.sql
... similar to perfSeqCache10.sql but on a different table ... - perfSeqCache10000.sql
... similar to perfSeqCache10.sql but on a different table ... - perfSeqCache100000.sql
... similar to perfSeqCache10.sql but on a different table ...
Each script prints a number of seconds that represents duration of the script execution. Those numbers are gathered together as test results.
Test results
The test cases described above were executed in four scenarios:
- Sequentially (one by one): simple, sequence without cache, sequence with cache 10, … sequence with cache 100k.
- All in parallel. SQL sessions were started from simple to sequence cache 100k.
- Sequentially from sequence cache 100k to simple.
- All in parallel started from sequence cache 100k to simple.
The results are in the below table:
| Test description | simple | identity | seq no cache | seq cache 10 | seq cache 100 | seq cache 1k | seq cache 10k | seq cache 100k |
| Sequentially from simple to seq cache 100k | 253 | 298 | 515 | 313 | 286 | 306 | 253 | 243 |
| All in parallel started from simple to seq cache 100k | 1192 | 1214 | 1486 | 1248 | 1220 | 1206 | 1217 | 1207 |
| Sequentially from seq cache 100k to simple | 190 | 230 | 361 | 206 | 199 | 187 | 187 | 196 |
| All in parallel started from seq cache 100k to simple | 1324 | 1368 | 1596 | 1395 | 1373 | 1367 | 1367 | 1367 |
| Average | 740 | 778 | 990 | 791 | 770 | 767 | 756 | 753 |
Specific numbers are not important as they may vary from machine to machine. More important are relations (less than, greater than) in the same rows. Greatest numbers in each row are highlighted in red, lowest - in green, intermediate – in yellow/orange. The more green a value is, the fastest method is. One of the first observations is – sequence with no cache is the slowest. It is aligned with a common sense – each time a new number is requested, the database engine needs to read the current sequence value and increment it. For comparison, a sequence with cache 10 does it only every 10 requests.
To have a view from one more perspective, duration is represented by percentage of how much the method is slower comparing to the fastest one in the row.
| Test description | simple | identity | seq no cache | seq cache 10 | seq cache 100 | seq cache 1k | seq cache 10k | seq cache 100k |
| Sequentially from simple to seq cache 100k | 4,12 | 22,63 | 111,93 | 28,81 | 17,70 | 25,93 | 4,12 | 0,00 |
| All in parallel started from simple to seq cache 100k | 0,00 | 1,85 | 24,66 | 4,70 | 2,35 | 1,17 | 2,10 | 1,26 |
| Sequentially from seq cache 100k to simple | 1,60 | 22,99 | 93,05 | 10,16 | 6,42 | 0,00 | 0,00 | 4,81 |
| All in parallel started from seq cache 100k to simple | 0,00 | 3,32 | 20,54 | 5,36 | 3,70 | 3,25 | 3,25 | 3,25 |
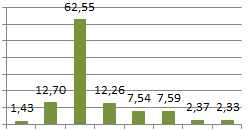
| Average | 1,43 | 12,70 | 62,55 | 12,26 | 7,54 | 7,59 | 2,37 | 2,33 |
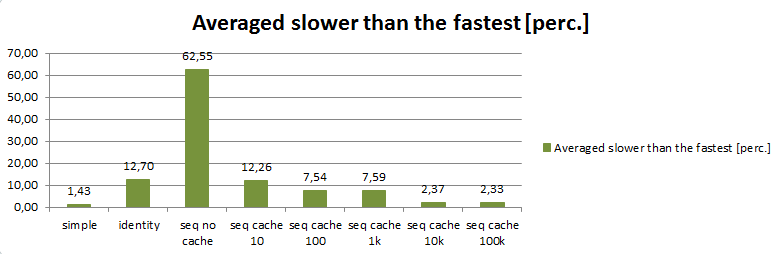
By looking at the average duration (the last row), as it was expected, the fastest was a test with hardcoded values (simple). There was the smallest effort required so there could not have been a surprise. It is also obvious, sequences without a cache are slowest. Additionally, it is clearly visible that sequences with bigger cache are better performing.
In my test, IDENTITY had performance similar to a sequence with a cache 10 but it may vary from a test to a test.
Summary
The test showed that a sequence object is a real competitor to IDENTITY. From performance perspective it can be even faster if cache is set properly. Cache about 100 should give an advantage to a sequence. Of course, it all depends on multiple conditions. If you do not generate values frequently, you may not notice a difference anyway no matter what cache size you choose. The decision about the size should also depend on sensitivity of your system on loosing numbers – after restarting SQL Server, cache is lost with all values prepared for usage - it is strongly connected to a cache size.
Nevertheless, I am not going to be afraid of sequences performance even for tables with a high rate of inserts. If I find sequences useful for my cases, I will use them.