 A few weeks ago, I described how to produce XML documents from relational data. There was a variety of methods - starting from a very straight forward FOR XML AUTO to a more flexible but also a complex one FOR XML PATH. This time, I will go to a totally opposite direction which is converting XML documents to relational data. This operation is called shredding. There is not only one method of doing this but today I will focus on using OPENXML for this purpose.
A few weeks ago, I described how to produce XML documents from relational data. There was a variety of methods - starting from a very straight forward FOR XML AUTO to a more flexible but also a complex one FOR XML PATH. This time, I will go to a totally opposite direction which is converting XML documents to relational data. This operation is called shredding. There is not only one method of doing this but today I will focus on using OPENXML for this purpose.
Storing data in XML documents and in tables have different advantages and disadvantages. For example tables make joining data easy so even if you receive data in XML format or even store it that way, you may want to convert it to tables even temporarily.
One of the possible ways is using OPENXML. It is a statement that returns a view with data based on parameters passed into it. There are two obligatory arguments:
- a handle to the XML document which is going to be converted; can be created using the sp_xml_preparedocument procedure,
- a path that points to nodes in the XML that are going to be converted into rows.
The third but optional argument is a flag indicating whether XML attributes, elements or both are sources of the data in the XML document.
Simple OPENXML usage
For demonstration purposes, I use an XML document produced in my previous article about XML. The below script extracts data about transactions and presents it as a table.
DECLARE @xml NVARCHAR(4000);
DECLARE @doc INT;
SET @xml =
'<transactions> <group> <name>gold members</name> <account id="1"> <name>Account 1</name> <transaction id="1"> <type>credit</type> <value>10000.0000</value> </transaction> </account> </group> <group> <name>regular members</name> <account id="2"> <name>Account 2</name> <transaction id="5"> <type>payment</type> <value>-103.0000</value> </transaction> </account> </group> <group> <name>regular members</name> <account id="3"> <name>Account 3</name> <transaction id="2"> <type>credit</type> <value>3.9500</value> </transaction> </account> </group> </transactions>';
EXEC sp_xml_preparedocument @doc OUTPUT, @xml;
SELECT *
FROM OPENXML(@doc, '/transactions/group/account/transaction', 11)
WITH (id INT, type NVARCHAR(255), value MONEY);
EXEC sp_xml_removedocument @doc;
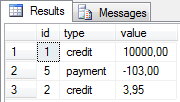
At the beginning the sp_xml_preparedocument procedure is used to create DOM from the XML document. The DOM object gets a handle assigned (@doc) which is used for referencing in the OPENXML statement. The /transactions/group/account/transaction points to nodes in the document that are converted to rows. The number 11 indicates that both: attributes and elements store data. Other options are:
- 1 - only attributes are used
- 2 - only elements are used
The WITH part indicates columns that will be created in the result set. Names of the columns are names of the attributes/elements in the document at the same time. It means that the id column will contain data from the /transactions/group/account/transaction/id path, type will use data from the /transactions/group/account/transaction/type path and the database engine will look into /transactions/group/account/transaction/value path for the value column.
It is worth emphasizing that the id column comes from an attribute while two other columns are extracted from elements. The flag argument of OPENXML that is set to 11 allows that. If 1 was used, the type and value columns would contain NULL values. If 2 was used, the id column would be NULL.
Obviously, as the DOM object was created, it had to be destroyed at the end. The sp_xml_removedocument procedure did exactly that.
Extracting data from different levels
The previous example showed the whole concept of shredding XML documents to tables with OPENXML statement. Although, I believe you remember that I was able to produce the XML document with only one query but the above example extracts only a part of data. Why could not I convert the whole XML document in one shot, not only the transaction nodes? Let's assume I want to get a table with the following columns:
- group name
- account id
- account name
- transaction id
- transaction type
- transaction value
They all describe somehow a transaction but this data comes from different nesting levels from the XML document. Fortunately, OPENXML allows being more precise in directing the SQL Server engine what is the source of data. The exact path can be defined separately for each column in the WITH clause as in the below script.
DECLARE @xml NVARCHAR(4000);
DECLARE @doc INT;
SET @xml =
'<transactions> <group> <name>gold members</name> <account id="1"> <name>Account 1</name> <transaction id="1"> <type>credit</type> <value>10000.0000</value> </transaction> </account> </group> <group> <name>regular members</name> <account id="2"> <name>Account 2</name> <transaction id="5"> <type>payment</type> <value>-103.0000</value> </transaction> </account> </group> <group> <name>regular members</name> <account id="3"> <name>Account 3</name> <transaction id="2"> <type>credit</type> <value>3.9500</value> </transaction> </account> </group> </transactions>';
EXEC sp_xml_preparedocument @doc OUTPUT, @xml;
SELECT *
FROM OPENXML(@doc, '/transactions/group/account/transaction', 11)
WITH (groupName NVARCHAR(255) '../../name', accountId INT '../@id', accountName NVARCHAR(255) '../name', transId INT '@id', transType NVARCHAR(255) 'type', transValue MONEY 'value');
EXEC sp_xml_removedocument @doc;
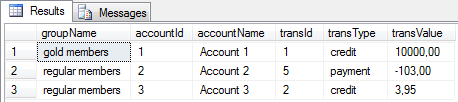
There are a few interesting items:
- I still used the same main path to the transaction - /transactions/group/account/transaction.
- I used a relative path to data for each column. For example groupName used ../../name which is two levels above the transaction nodes. It is an equivalent of /transactions/group/name.
- To distinguish an attribute name from an element, the @ sign was used like you can see for the transId or accountId columns.
Last word
Probably some of you reading about creating a DOM object for an XML document wondered isn't it an overhead compared to parsing it on the fly? Hmm ... yeah. It might be. If you need to convert multiple rows with XML documents to a table, it might be a performance killer to create a DOM object separately for each row. On the other hand, if you want to execute many queries with OPENXML on the same document, this solution may be perfect.
Nevertheless, there are no solutions that are always perfect or terrible. This one is not an exception.
Look forward to my next articles about XML support in SQL Server, I may write about the second option of shredding XML documents to relational form.