 Recently, I have noticed my colleagues developing database applications struggle with similar problems. This problem is database versioning. It is a little bit surprising because a need of versioning database or schema structure is not new. I can risk even saying – it is absolutely common for almost all systems based on a database. What is interesting – solving this problem is quite easy, well described and there are some tools to support it. Some of them are free.
Recently, I have noticed my colleagues developing database applications struggle with similar problems. This problem is database versioning. It is a little bit surprising because a need of versioning database or schema structure is not new. I can risk even saying – it is absolutely common for almost all systems based on a database. What is interesting – solving this problem is quite easy, well described and there are some tools to support it. Some of them are free.
Knowing how many people do not know how to handle those issues, I have decided to make this video. Actually, I plan at least two presentation about it: in this one I will described the problem and show a sample solution, in the next one I will try to show this knowledge in practice using one of the free tools available on the market.
This article is available on youtube as a presentation.
Database versioning
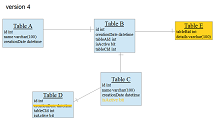
What is database versioning? By this term I mean versioning schema structure. For example, you have a system in version 1, 2, 3. 3 is the newest one. Each of this version has its own database schema structure – a set of tables, columns, foreign keys, triggers etc.
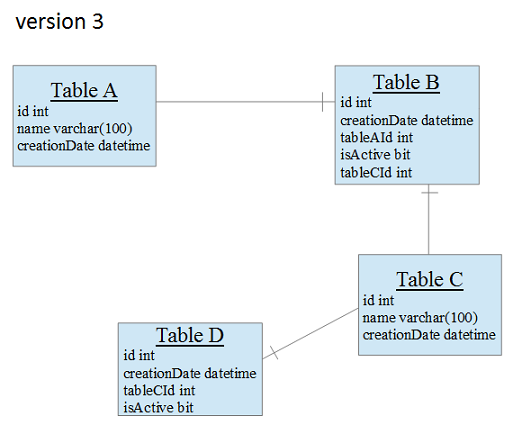
And you are currently working on version 4. During new version development you need to add some tables to the database, add some columns, change data types of some columns etc. to the scheme structure of version 3.
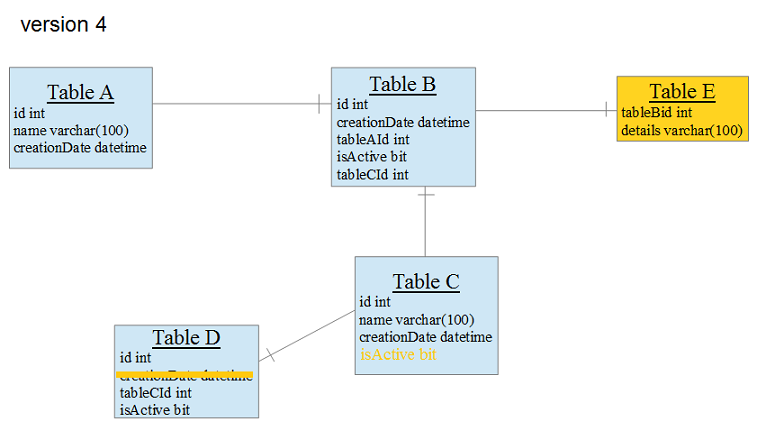
Once the development of version 4 is complete, you need to be able to replace old versions of your system with the newest one – version 4. No matter who hosts the databases – you or your customer. The biggest question in this topic is – how can you do this? How can you upgrade the database system from version 1, 2, 3 to version 4?
So those are the main questions that I would like to answer in this article.
Application development and deployment
What is interesting, an answer to this question is problematic much more often to database developers than to application developers. If you talk to a Java developer about it, he/she will not identify it as a big problem because application developers know exactly how to handle this. They have tools and knowledge about it. Knowing that, I would like to start with application versioning, just to have something to refer to.
Application development and deployment process can be split to 3 phases: coding, building and deployment.
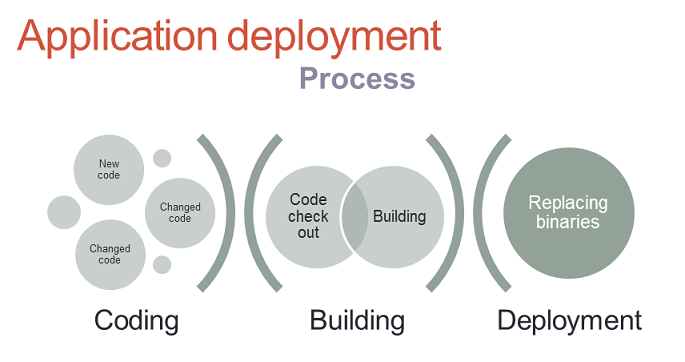
In the coding phase, a developer has some features to implement and defects to fix so he/she adds new code and changes some existing code. The whole code is checked into a source code repository. Once the developers think the code is ready for the next phase, the building phase starts. First, the newest source code needs to be checked out from the repository and then it can be converted to an executable binaries. At the end of this phase, the developers have an executable version of the application. And now, there is time for the most crucial part from this presentation perspective – deployment. But actually, application deployment is extremely simple – it is just replacing old binaries with the new ones. It is like a copy-paste with replacement. Simple, isn’t it?
Why does it work for application?
There is one main reason – an application does not have a business state when it is idle so existing installation can be overwritten with new binaries.
Database develompent and deployment
How about database deployment?
Is it the same for a database? No. A database contains data which makes a business state of the system. This data must be preserved. A database cannot be simply overwritten.
Concept
At this point, I would like to present you a concept of incremental SQL scripts that modify a database without overwriting it.
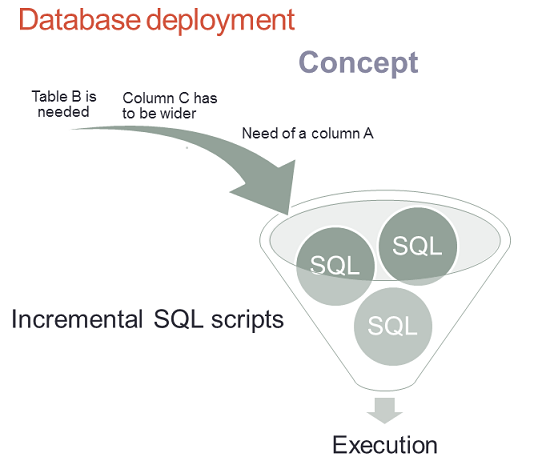
At the beginning you have a set of business or technical requirements for your system like you need a new table B, column C needs to be wider and a new column A is necessary in one of the tables. You need to convert them to SQL scripts that incrementally modify a databases so finally it fulfills all of those requirements. All those scripts should be queued in the code repository and wait for deployment time. During the deployment the SQL scripts are executed in the order of adding them to the repository so: table B is created, column C is extended and column A is created.
Examples
Let’s see some examples.
Need 1: I need a new table for storing some additional data so I write a SQL script – create table A …
Need 2: My data requires a longer column so my SQL script is supposed to extend it not to recreate it, because I don’t want to lose my data in this column.
Main principle of incremental SQL scripts is to preserve data that already exists.
That is pretty much it for this article. As I mentioned at the beginning, I plan to make another one in this topic to show you how you can use a tool that is available on the market to implement this concept.