 Window functions are not new in SQL Server but SQL 2012 shed a new light on them. In the past, they were mostly used for ranking rows with RANK, DENSE_RANK, NTILE and ROW_NUMBER functions (Ranking Functions (Transact-SQL)). Aggregations could also be used in SQL Server 2008 but aggregates were calculated only for whole partitions. It was a nice feature which simplified some queries. Next big step was made in SQL Server 2012 which made them more powerful by supporting frame clauses. Besides splitting data to partitions, a developer can define a frame which moves a row by row. Then, data in the frame can be aggregated.
Window functions are not new in SQL Server but SQL 2012 shed a new light on them. In the past, they were mostly used for ranking rows with RANK, DENSE_RANK, NTILE and ROW_NUMBER functions (Ranking Functions (Transact-SQL)). Aggregations could also be used in SQL Server 2008 but aggregates were calculated only for whole partitions. It was a nice feature which simplified some queries. Next big step was made in SQL Server 2012 which made them more powerful by supporting frame clauses. Besides splitting data to partitions, a developer can define a frame which moves a row by row. Then, data in the frame can be aggregated.
Now, calculating of moving averages is finally easy.
In this article I will present examples of using window aggregate functions in SQL Server 2012.
Test data
For demonstration purposes I created the following structure.
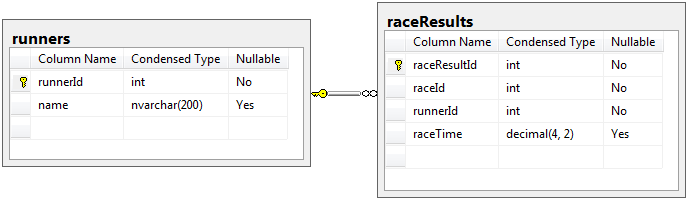
The following script creates the tables and inserts test data:
create table runners (
runnerId int not null,
name nvarchar(200),
constraint PK_runner primary key (runnerId) );
create table raceResults (
raceResultId int not null,
raceId int not null,
runnerId int not null,
raceTime decimal(4, 2),
constraint PK_raceResults primary key (raceResultId)
);
alter table raceResults
add constraint FK_raceResults_runnerId foreign key (runnerId) references runners(runnerId);
insert into runners (runnerId, name)
values (1, 'Tom'), (2, 'Andrew'), (3, 'John');
insert into raceResults (raceResultId, raceId, runnerId, raceTime)
values (1, 1, 1, 10.5), (2, 2, 1, 10.43), (3, 3, 1, 10.38), (4, 4, 1, 10.36), (5, 5, 1, 10.21), (6, 6, 1, 10.2), (7, 7, 1, 10.19), (8, 8, 1, 10.14), (9, 9, 1, 10.08), (10, 10, 1, 10.06);
insert into raceResults (raceResultId, raceId, runnerId, raceTime)
values (11, 1, 2, 10.4), (12, 2, 2, 10.43), (13, 3, 2, 10.2), (14, 4, 2, 10.1), (15, 5, 2, 9.95), (16, 6, 2, 10.1), (17, 7, 2, 10.03), (18, 8, 2, 11.14), (19, 9, 2, 11.03), (20, 10, 2, 11.3);
The schema represents result of sprint races (100 meters running races). There are 3 sprinters in runners table:
| runnerId | name |
| 1 | Tom |
| 2 | Andrew |
| 3 | John |
First two participated in 10 races. The results are stored in raceResults table:
| raceResultId | raceId | runnerId | raceTime |
| 1 | 1 | 1 | 10.50 |
| 2 | 2 | 1 | 10.43 |
| 3 | 3 | 1 | 10.38 |
| 4 | 4 | 1 | 10.36 |
| 5 | 5 | 1 | 10.21 |
| 6 | 6 | 1 | 10.20 |
| 7 | 7 | 1 | 10.19 |
| 8 | 8 | 1 | 10.14 |
| 9 | 9 | 1 | 10.08 |
| 10 | 10 | 1 | 10.06 |
| 11 | 1 | 2 | 10.40 |
| 12 | 2 | 2 | 10.43 |
| 13 | 3 | 2 | 10.20 |
| 14 | 4 | 2 | 10.10 |
| 15 | 5 | 2 | 9.95 |
| 16 | 6 | 2 | 10.10 |
| 17 | 7 | 2 | 10.03 |
| 18 | 8 | 2 | 11.14 |
| 19 | 9 | 2 | 11.03 |
| 20 | 10 | 2 | 11.30 |
I will use this data for demonstrating usage of window aggregate functions.
Window aggregate functions in general
They are aggregate functions like AVG, SUM, COUNT but defined on a frame of rows using OVER keyword. The rows are grouped using PARTITION BY and sorted using ORDER BY clause. The frame of rows is defined once for the whole function but the particular set of rows is chosen to the frame separately for each row. As a result, for each row the window aggregate function is calculated and each row has separate result of the function.
The frames can be defined in a few different ways. I describe them below.
Frame is common for all rows
The simplest case is when the frame is the same for all rows in the query. To make it more practical, lets take a look at the following case based on runners and raceResults tables.
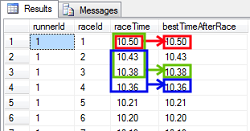
- Problem - I need to display all Tom's races with time and overall Tom's best time for comparison.
It can be achieved by this query:
select raceId, raceTime, min(raceTime) over () as timeToRecord
from runners r
left join raceResults res on r.runnerId = res.runnerId
where name = 'Tom'
order by res.raceId;
Below is the result of execution.
Three colors show source of data for calculation of the first three timeToRecord values. The first value marked in red was calculated based on all ten rows from raceTime column - a minimum of the values was found in this case. The second value marked in green is the same because it was calculated on the same values - all ten raceTime values were searched for the lowest number. The third timeToRecord value is no different, because like the previous two values, it was calculated using the whole set of values.
In this case the frame is constant and the same for all rows - red, green, blue and others.
Separate frames
Now, when the simplest case is left behind, the query can get a little more complex.
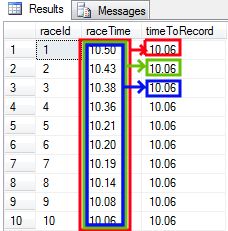
- Problem - You may want to calculate best times separately for all runners.
Separate frames will be needed for different runners. In our case - two, but actually we don't care about the exact number as a definition of the frames are the same. SQL Server takes care of using proper number of frames. Frames duplication can be done by PARTITION BY keyword:
select r.runnerId, raceId, raceTime, min(raceTime) over (partition by r.runnerId) as timeToRecord
from runners r
left join raceResults res on r.runnerId = res.runnerId
order by r.runnerId, raceId;
Result is as below:
As you can see above, there are two frames (red/green and blue). One for each distinct runnerId. It was defined by PARTITION BY r.runnerId clause. It is worth to notice, the frames do not move. All timeToRecord values for one runner are the same.
Expanding frames
True power of SQL Server 2012 in area of window aggregate functions comes from frames that can change. In this section I will show how frames can expand.
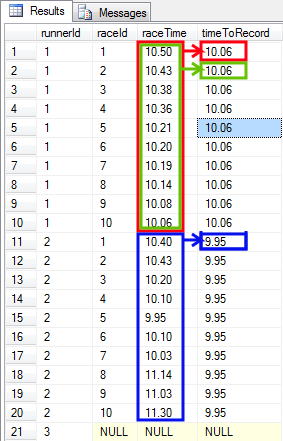
- Problem - For each race I need to display the current best time of the runner from the first race till the current one. This data is needed to display best times of each runner AFTER each race.
To achieve this I need to go further with narrowing a range of rows included in the calculation. When I calculate the required value for raceId=3, I should find the best time of the runner from races 1, 2 and 3. RaceId=4, 5, 6 ... have not taken place yet so I should not include them. This "narrowing" can be done by using BETWEEN ... AND ... clause in the OVER section.
select r.runnerId, raceId, raceTime,
min(raceTime) over (partition by r.runnerId order by raceId rows between unbounded preceding and current row) as bestTimeAfterRace
from runners r
left join raceResults res on r.runnerId = res.runnerId
order by r.runnerId, raceId;
You can see below that a size of the frame depends on the raceId for which min(raceTime) is calculated.
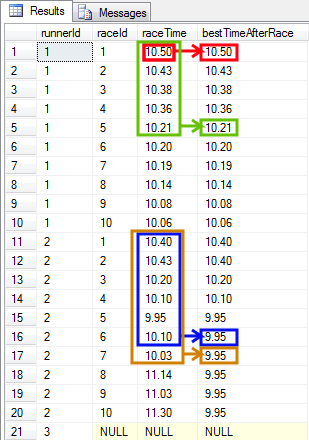
The frame contains all raceTimes from the first race (because of UNBOUNDED PRECEDING clause) to the current race (because of CURRENT ROW clause). There is a separate frame for each runner (because of PARTITION BY r.runnerId clause).
Moving frames
In the previous example (expanding frames) the beginning of the frame was tied to the first row of the partition, the ending of the frame was moving along with the current row making the whole frame to expand. Now, I will force the frame to move as a whole not just the ending.
- Problem - I want to present the best time of last 3 races. I want the result to be presented for each race. Each runner should be considered separately.
The query solving the problem is very similar to the previous one. I need to modify only the part which is responsible for defining the beginning of the frame - UNBOUNDED PRECEDING needs to be changed to 2 PRECEDING.
select r.runnerId, raceId, raceTime,
min(raceTime) over (partition by r.runnerId order by raceId rows between 2 preceding and current row) as bestTimeAfterRace
from runners r
left join raceResults res on r.runnerId = res.runnerId
order by r.runnerId, raceId;
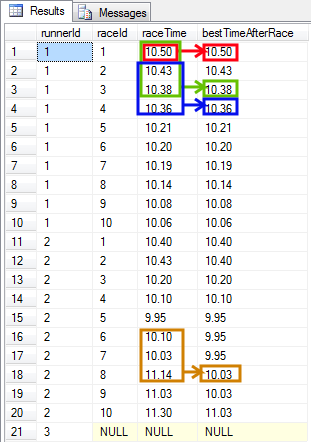
In this example the frames are not longer than 3 rows because they look at 2 PRECEDING rows and the CURRENT ROW. If enough preceding rows are not available (for the first and the second row), then only available rows are brought for calculation and the frame is shorter. I think about such construct as of fixed-length frames that are stepping along with the rows for which the calculation is being made.
Other examples
Of course, the queries presented above are just examples. Their purpose was to show different ways of using window aggregate functions. Please take a look at more examples below:
- A frame with 3 preceding, the current and 1 following row:
min(raceTime) over (partition by r.runnerId order by raceId rows between 3 preceding and 1 following)
- A frame with the 3rd preceding and the 2nd preceding row:
min(raceTime) over (partition by r.runnerId order by raceId rows between 3 preceding and 2 preceding)
- A frame with the current row and all consequtive rows:
min(raceTime) over (partition by r.runnerId order by raceId rows between current row and unbounded following)
Read more on: