 SQL Server has a few options of storing unstructured data in a way that querying using SQL is possible. One of them is the FILESTREAM feature. In some sense, it joins benefits of data in tables and files in a filesystem. Relevant data can be easily selected, inserted, updated and deleted using SQL as if it was a simple data type but read operations are as fast as it was reading files from a filesystem. In this article, I will show how to enable the FILESTREAM feature on an SQL Server 2014 instance, configure a database and use FILESTREAM for storing data.
SQL Server has a few options of storing unstructured data in a way that querying using SQL is possible. One of them is the FILESTREAM feature. In some sense, it joins benefits of data in tables and files in a filesystem. Relevant data can be easily selected, inserted, updated and deleted using SQL as if it was a simple data type but read operations are as fast as it was reading files from a filesystem. In this article, I will show how to enable the FILESTREAM feature on an SQL Server 2014 instance, configure a database and use FILESTREAM for storing data.
What is FILESTREAM
FILESTREAM is a SQL Server feature that is a bridge between SQL Server and a file system. It can be used for storing BLOBs as files on disk instead of wrapping them in rows and saving them in regular SQL Server file groups. In such case, a database instance does not have to take care of all stages of processing read and write operations but on some level Win32 file system interfaces are used. In fact, SQL Server has to ensure transactions and consistency of data and expose access to BLOBs through T-SQL. But many other tasks are done on the file system level.
Such architecture reduces amount of work that SQL Server has to do when dealing with BLOBs. It directly results in reduced buffer pool consumption which could be significant if objects were really large and stored in a traditional way using regular file groups.
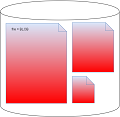
The below diagram represents the traditional way of storing BLOBs in SQL Server.
A database has file groups that consist of files. A file has extends were tables data are stored. Tables data is divided to rows and a part of rows data can be BLOBs. Physically, only files are visible from the file system perspective. Everything inside is handled by the database engine. It includes locating, reading, writing, caching, splitting data etc. It is quite a lot of responsibility.
In case of storing BLOBs using the FILESTREAM feature, a lot of responsibility is delegated to the file system. The below diagram presents the concept:
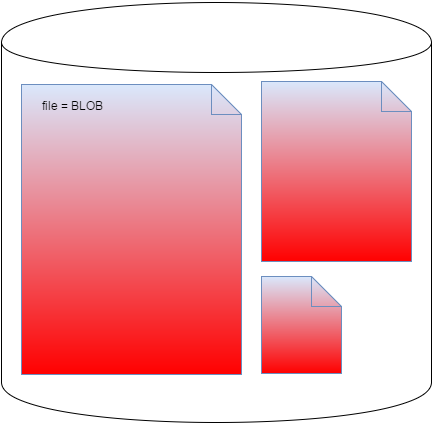
It looks simple and actually it is. Each BLOB is stored as a separate file in the file system. It is a one to one relation. BLOB's reading and writing is on the file system side. Database is only a coordinator in this case.
Enabling FILESTREAM
Before FILESTREAM can be used, it has to be enabled on the instance. To do this, go to Configuration Manager, select SQL Server Services and double click the instance you would like to have FILESTREAM enabled.
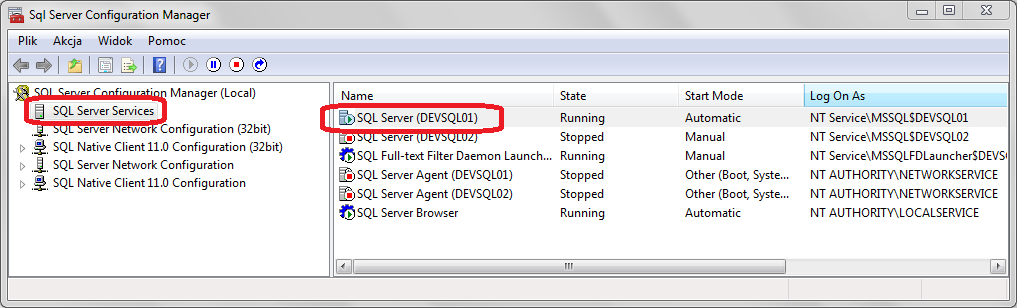
The properties window should show up. Go to the FILESTREAM tab and check Enable FILESTREAM for Transact-SQL access, Enable FILESTREAM for file I/O access and Allow remote clients access to FILESTREAM data. Not all three options are required to be chosen, for more details refer to the documentation.
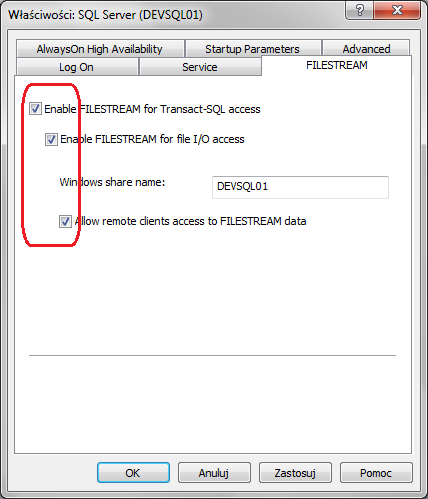
Once it is done, restart the SQL Server service.
Open SQL Server Management Studio, connect to the instance and execute the following script that sets access level.
EXEC sp_configure filestream_access_level, 2
RECONFIGURE
Creating structures for FILESTREAM
Once FILESTREAM is enabled on the instance level, some necessary structures have to be created on the database level such as a file group where BLOBs are going to be stored.
USE [master]
GO
ALTER DATABASE [MyDatabase] ADD FILEGROUP [PRIMARY_FILESTREAM] CONTAINS FILESTREAM
GO
ALTER DATABASE [MyDatabase]
ADD FILE (
NAME = N'MyDatabase_filestream',
FILENAME = N'D:\Microsoft SQL Server\MSSQL12.DEVSQL01\MSSQL\DATA\MyDatabase_filestream'
)
TO FILEGROUP [PRIMARY_FILESTREAM]
GO
USE [MyDatabase]
GO
The above script adds a PRIMARY_FILESTREAM file group for FILESTREAM data and defines a catalog for BLOB's files. It is provided to the FILENAME parameter but it actually is a directory. It is just a standard SQL construction for adding a file to a file group.
I can see result of this operation on the file system:
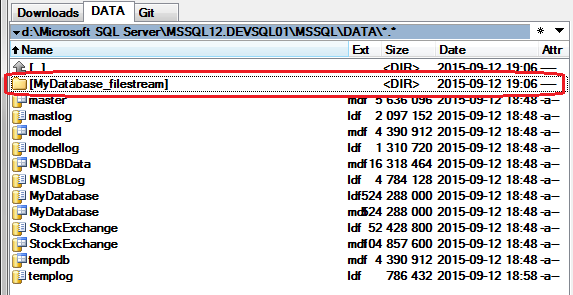
If all above operations were successful, a table with BLOBs stored using FILESTREAM can be created:
CREATE TABLE images(
id UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE,
imageFile VARBINARY(MAX) FILESTREAM
);
GO
As you can see, my table has id column with a set of properties and constraints like UNIQUEIDENTIFIER, ROWGUIDCOL, NOT NULL and UNIQUE. They are required for tables with FILESTREAM columns. The most important column for me is imageFile. It is VARBINARY(MAX) with the FILESTREAM property chosen.
Inserting objects
The sample table can be filled with sample data. I have chosen three pictures that will be added using INSERT statements with the OPENROWSET function.
INSERT INTO images(id, imageFile)
SELECT NEWID(), BulkColumn
FROM OPENROWSET(BULK 'd:/tmp/20150627_132729.jpg', SINGLE_BLOB) as f;
INSERT INTO images(id, imageFile)
SELECT NEWID(), BulkColumn
FROM OPENROWSET(BULK 'd:/tmp/20150627_180121.jpg', SINGLE_BLOB) as f;
INSERT INTO images(id, imageFile)
SELECT NEWID(), BulkColumn
FROM OPENROWSET(BULK 'd:/tmp/20150627_180211.jpg', SINGLE_BLOB) as f;
Data insertion can be confirmed by selecting them:
SELECT *
FROM images;

Of course, it makes the most sense to insert and select such objects using a programming languages like Java or C#. I show here only the concept.
At the end, I can show you how the objects from the table are visible on the file system:

One to one mapping of BLOBs and files is clearly visible.
Summary
The FILESTREAM feature is an alternative to storing large objects in database tables. According to Microsoft documentation, read operations are faster in this case if the objects are big enough. I hope to verify it soon and share the results with you.