Hazelcast is one of the most popular caches. We would be shocked if it didn't integrate with Spring Boot. Basic integration is quite easy but not as simple as many could expect. One of the famous Hazelcast issues is a lack of good backward compatibility. The developers change the interfaces way too often. See how to integrate Spring Boot 3 with Hazelcast 5 in a simple example.
Spring Boot 3 cache
Spring Boot 3 has a special starter to support caching. It can easily handle these cache providers:
- Generic
- JCache
- Hazelcast
- Infinispan
- Couchbase
- Redis
- Caffeine
- Cache2k
- Simple
To start, you need to add spring-boot-starter-cache dependency.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
Using the starter, you let Spring Boot take care of most of the configuration and set some defaults. It saves a lot of work.
Some time ago, I published an article about Spring Boot 3 integration with Caffeine cache. You find there all the steps necessary to configure Caffeine as a cache manager in Spring Boot.
Hazelcast
Hazelcast is a platform for data caching and distributed computing. It comes with a set of tools and libraries that allow managing the platform. As it is a distributed cache, it is often used for horizontal scaling big services.
Yes, your impression is correct - it is one of the most advanced broadly used caching platforms. Because of that size, it contains a lot of configuration options, which makes it a little bit more difficult to set up than for example, Caffeine. From a higher perspective, you have to choose the architecture first:
- client-server
In this topology, the cache is implemented as a separate service or a set of services acting as a distributed cache. But the client services, that use the cache, connect to it over the network.
A possible simple option is as presented in the diagram below - two client computational services that connect to a separate (remote) Hazelcast cache.
It is useful when the client services are big and consume enough memory to not overload them additionally with cache data. Then, it is better to keep this data separately on different servers.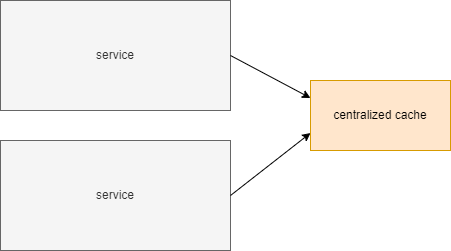
- embedded
It is a simpler topology as it does not require additional services or servers. Distributed cache is a part of each client service - it is embedded in the client. Of course, all cache nodes may be connected in the cluster to form a distributed cache. Thanks to that, they will exchange data to not compute data multiple times. As they are embedded locally, accessing the cache does not include a network delay.
If your cached data is not big, and the number of services that need is small, it might be a good option to consider.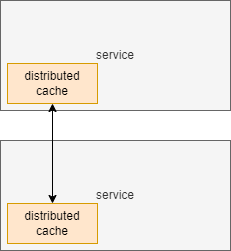
Later in the article, I will show you how to configure Hazelcast as an embedded cache.
Spring Boot Starter Cache
As I already mentioned above, the first step is to add spring-boot-starter-cache dependency to the project.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
Then, I add the @EnableCaching annotation on the main class - the one with the @SpringBootApplication annotation. Alternatively, you can add it to any configuration class.
@EnableCaching
@SpringBootApplication
public class HazelcastSpringBootApplication {
public static void main(String[] args) {
SpringApplication.run(HazelcastSpringBootApplication.class, args);
}
}
I add the @Cacheable annotation on a service method which result I want to cache. In this example, the StatsService.getUserStats(int userId) simulates reading data from a database. It can take a relatively long time, I want to cache the result. The @Cacheable annotation indicates that this method result should be cached, the cache name and the key are provided as arguments.
@Service
public class StatsService {
private final Random random = new Random();
@Cacheable(cacheNames = "stats", key = "#userId")
public UserStats getUserStats(int userId) {
System.out.println("Calculating stats for userId=" + userId);
return new UserStats(userId, getRequestsCountFromDb(userId));
}
private int getRequestsCountFromDb(int userId) {
// heavy operation
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return random.nextInt();
}
}
Hazelcast configuration as an embedded cache
At this point, we have nowhere told Spring to use Hazelcast. It is time to fix that mistake. I do this by adding hazelcast-spring dependency.
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-spring</artifactId>
<version>5.3.6</version>
</dependency>
Generally, that could be enough. It should work, but it is not very useful in the way it is. Hazelcast initiates with the default configuration. Among other values, it sets expiration time to indefinite future, so values cached once are never expired. We don't want that.
To configure the Hazelcast cache as a local embedded instance, I can use programmatic config. I create a configuration class, that creates ClientConfig and HazelcastInstance beans.
@Configuration
public class CacheConfig {
@Bean
public HazelcastInstance hazelcastInstance() {
HazelcastInstance instance = Hazelcast.newHazelcastInstance();
instance.getConfig().addMapConfig(new MapConfig("stats").setTimeToLiveSeconds(5));
return instance;
}
@Bean
public ClientConfig clientConfig() {
ClientConfig cfg = ClientConfig.load();
cfg.setClusterName("statsCluster");
return cfg;
}
}
The class is annotated with @Configuration, which tells Spring to process this class before other beans like components and services. A few elements here are worth describing:
- The first bean is a Hazelcast instance. It is important because it creates a cache instance, which will keep our cached data. You may notice in other tutorials or examples on other blogs, that people create Hazelcast clients instead. It is also correct but is suitable for the client-server topology, not the embedded one.
- The addMapConfig method allows providing MapConfig with non-default configuration values. If you want to customize the cache, this is the place. Check yourself what other options MapConfig has.
My configuration sets the time to live to 5 seconds, so after 5 seconds after adding a value to the cache, it is marked as expired and will no longer be used.
Testing
That is basically it, but let's do one more step and see if it works fine. I create a test class as below.
@SpringBootTest
class StatsServiceTest {
@Autowired
private StatsService statsService;
@Test
void shouldGetUsersStatsInLoop() throws InterruptedException {
long timeStart = System.currentTimeMillis();
for (int i = 1; i <= 10; i++) {
System.out.println("Loop number " + i);
statsService.getUserStats(1);
statsService.getUserStats(2);
Thread.sleep(1000);
}
System.out.println("Duration " + (System.currentTimeMillis() - timeStart) + " ms");
}
}
The test calls the getUserStats method in a loop with a delay of 1 second. Thanks to printing some text to the standard output, we will know when the heavy method is really executed. I run the test, and I get these results:
Calculating stats for userId=1
Calculating stats for userId=2
Loop number 2
Loop number 3
Loop number 4
Loop number 5
Calculating stats for userId=1
Calculating stats for userId=2
Loop number 6
Loop number 7
Loop number 8
Loop number 9
Calculating stats for userId=1
Calculating stats for userId=2
Loop number 10
Duration 16441 ms
Real values are read in the first iteration. The values are cached, so the next 4 iterations don't need to compute them again. But then 5 seconds passed and the cached objects expired, so the 6th iteration required real values again. And so on.
It shows that the basic Hazelcast configuration worked and respected the time-to-live setting.
The whole code is in the Git repository.