Caching has different faces. It can live long or short, be local or distributed, and use various eviction strategies. Surprisingly, there are many options to choose from. Some can be implemented quickly and some will require adding new technology to the project. What should I choose for my application? Are there any universal solutions?
Why caching?
I think each piece of software, at some point in its life, faces performance challenges. If that happened to your application, congratulations! It probably means it is successful. But be careful and solve the performance problems quickly to use your 5 minutes of popularity well.
If you have taken my course Database performance for Hibernate developers, you should already know that the first place to look for reasons for bad performance is the architecture and design. Yes, I know, it is now easy to change the architecture. Actually, caching is sometimes a good way to improve performance. So what is the deal with caching? Let's consider a very common case - a web application.

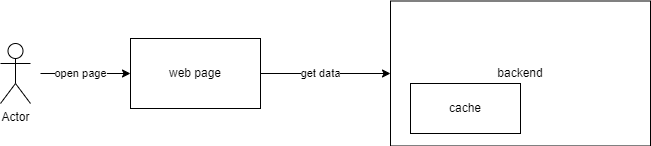
A user opens a web page, then besides the static files like HTML, CSS, and images, it requires requesting data from the backend service. Usually, many different types of data are requested at this point. But for simplicity purposes, let's focus on one of them. This get data operation may be for example getting a list of products in an online shop, a list of users for the admin to manage, etc. If that operation takes a long time to finish, the user will have to wait, and in the best-case scenario, the web page will not be complete until the data is fully received.
As I mentioned earlier, it is worth checking other possibilities for performance improvement: is the data stored in the right structure, is this data really needed, and can it be reduced somehow? But you may get to the conclusion that caching is the best option. How would that work?
The first thought of the architecture would be to add caching somewhere inside the backend service. Get the data from the cache if possible, and if not, calculate it and then cache it for future use. Yes! It is a very common generic approach. But ... it is not the only option and you have still many details to choose from. See the whole spectrum below.
Caching on demand vs. pre-caching
If you think about caching, you probably imagine this scenario:
- Data is requested.
- The cache is checked, if the requested data is there.
- If it is not there, it is calculated in a normal way, and added to the cache.
- If it is there, it is retrieved from the cache.
- The requested data is returned.
It is a popular way of how the cache works, and it suits many cases. It is called an on-demand cache. In the beginning, it is empty, until the data is needed for the first time. Then, the data is computed and then added to the cache. If no data is requested, the cache remains empty.
| Pros | Cons |
|
|
This approach works really well in most cases, but notice the cons side. The first request must be computed as it will not be in the cache. So if the cached data is shared between users, the first user will see no performance improvement after introducing the cache. Their requests cause caching responses, that will help subsequent users not themselves. If you think about it, such caching will reduce the mean waiting time, but not the maximum waiting time. The first user may still report a terrible performance.
If such a case is problematic, there is a different option - pre-caching. The concept is to build a cache before any request comes to the application - it can be once a day in the morning, and/or on the application startup. Unfortunately, there is an important question to answer - which data should be cached - all of them? I guess, that not all of them, it could be a waste of space for caching. Probably some data is old and rarely needed, and keeping them in the cache is a waste of resources. The challenge appears naturally, you have to understand the current application usage and identify what data deserves caching.
| Pros | Cons |
|
|
Sometimes pre-caching is especially a tempting option. If getting the data in a normal way takes a lot of time, for example, 10 minutes in online traffic, it is simply unacceptable for the user to wait that amount of time for a web page to load. Pre-caching is a way to compute data ahead of time and already have it in the cache before the user actually needs it.
Local vs. centralized vs. distributed
A small simple cache is usually local. It means, that a service that needs caching maintains its own cache and retrieves data from the cache is available or otherwise computes a result. In implementing a local cache, it is especially important to put some size restrictions in place. If more and more values are added to the cache, it may grow too much and cause OutOfMemoryException and a crash of the service. Designing the cache maximum size, you must take into consideration other activities performed by the service as well as all other objects that may exist in the heap space.
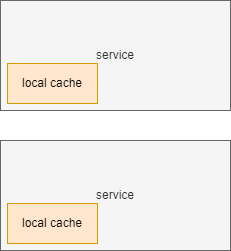
All of that may still be completely fine and manageable in one node. But if you have the same service deployed on 5 nodes and the traffic is load-balances between them, all those nodes will have their own local cache. Possibly duplicating cached values.
| Pros | Cons |
|
|
Alternatively, a cache may become a dedicated service. The business service may call the cache service to check if a value is cached there or otherwise compute it locally and send it to the cache service for future usage. A significant benefit of such a solution is the amount of memory, that can be dedicated to the centralized cache. The cache service may be deployed on a dedicated node and exclusively use all its memory.
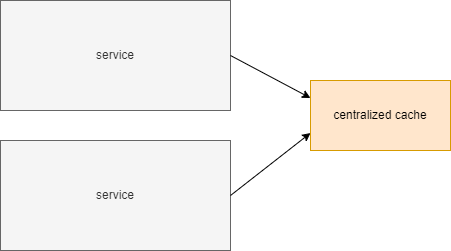
Unfortunately, having it on a separate node increases network traffic. Every cache check requires sending a request to another node. It may seem unimportant, but it may be significantly slower than checking a local cache.
| Pros | Cons |
|
|
If it is worth the effort in your case, you may try to combine the benefits of both: local and centralized approaches into a distributed solution. You may stay with a local cache for each node, but let them know about each other. Then, each local cache is aware that there are others out there, so if it does not have the value that the service is looking for, it may check its colleagues - they may have it and share it.
It is definitely the most complex approach of the above options. Luckily, there are commercial and open-source solutions, that can be used instead of implementing them on your own.
| Pros | Cons |
|
|
Summary
A cache can be implemented in many different ways. Various solutions come at different costs and effort. Surprisingly or not, the simplest option - a local on-demand cache is good enough for most real cases. Actually, before implementing any caching, analyze your case and choose wisely.